Trustwise Launches With $4 Million Round From Hitachi Ventures to Solve Generative AI Safety and Efficiency
Trustwise Optimize:ai reduced LLM operational costs by 80%, decreased carbon footprint by 64%, and detected 40% more AI safety and alignment issues than other vendors on the market
AUSTIN, TX – June 18, 2024 – Trustwise, a pioneer in generative AI application performance and risk management, today announced its official launch, the release of its Optimize:ai product, and $4 million in seed financing. Led by Hitachi Ventures with participation from Firestreak Ventures and Grit Ventures, this investment will enable the company to speed up the development of cost and risk optimized generative AI prototypes for various industries, accelerate its go-to-market and partnership strategy, and further its research initiatives.
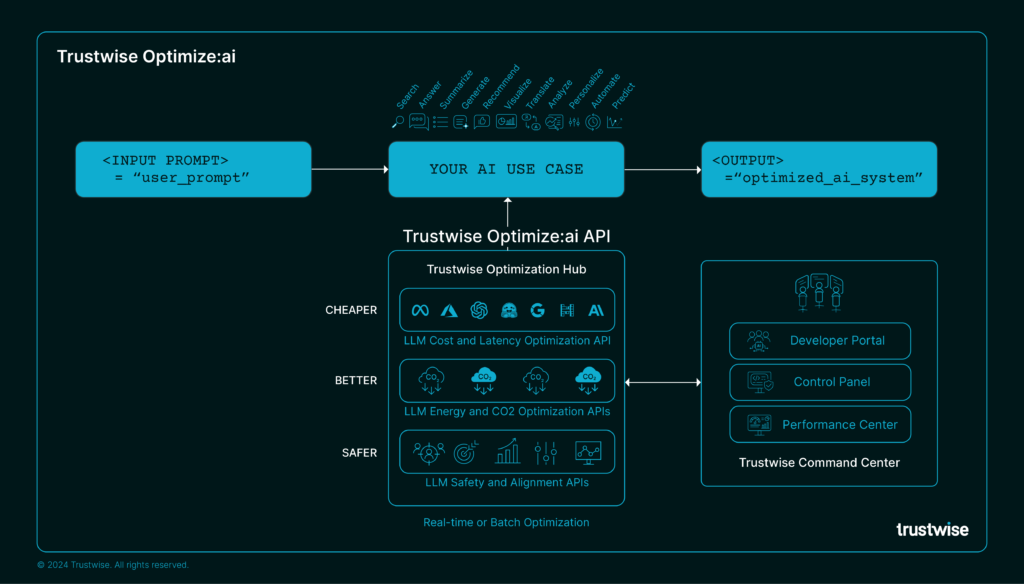
Trustwise Optimize:ai is a first-of-its-kind generative AI application performance and risk management solution that provides developers with an API to eliminate risks and reduce the growing costs associated with deploying large language models (LLMs) in high-stakes enterprise environments. By rigorously red-teaming and optimizing generative AI workloads using its advanced APIs, datasets, and AI safety and alignment controls, Trustwise safeguards enterprises from potential AI failures and excessive costs. Optimize:ai aligns with major AI standards and regulations, including the European Union AI Act, NIST AI RMF 1.0, Responsible AI Institute RAISE Safety and Alignment Benchmarks, and SCI ISO software carbon intensity standard.
“Enterprise leaders face a double-edged sword in AI strategy: while promising next-level innovation and productivity gains, LLMs also bring significant safety risks, cost burdens, and environmental impacts,” said Gayathri Radhakrishnan, partner at Hitachi Ventures. “Trustwise’s experienced and world-class team is set to provide the much-needed generative AI optimization capabilities that will enable developers to create safe, efficient, and high-performing AI systems.”
AI’s Risk Trifecta: Skyrocketing Expenses, Carbon Emissions and LLM Vulnerabilities
Generative AI systems too often produce inaccurate results, do not adhere to internal and external policies and regulations, and are costly and energy inefficient, with many instances of companies facing legal repercussions.
- Risk and safety:
Hallucinations and sensitive data leakage significantly erode user trust in AI systems, which is crucial for widespread adoption. According to GitHub Hallucinations Leaderboard, popular LLMs like GPT-3, LLaMA, Gemini, and Claude hallucinate between 2.5% and 8.5% of the time when summarizing text. - Skyrocketing demand and expenses:
Businesses are recognizing the potential of this technology, but they’re also cautious about the costs. AI cost worries have surged 14x in the past year according to a study by LucidWorks. - Environmental repercussions: A University of Massachusetts Amherst study found that training a common large AI model can emit more than 626,000 pounds (284 metric tons) of carbon dioxide equivalent, which is nearly five times the lifetime emissions of the average American car, including its manufacturing.
“At Trustwise, we understand the challenges enterprises face with generative AI, including safety risks, high costs, and environmental impacts,” said Manoj Saxena, CEO and founder of Trustwise. “For example, compared to a traditional Google search, a ChatGPT query costs around 36 times more, uses 1000 times more energy, and has safety issues like hallucinations and data leakage. After nearly two years of co-development with clients in highly regulated industries, the launch of Optimize:ai makes AI safe, compliant, and economically and environmentally viable.”
Trustwise Optimize:ai: The New Standard for GenAI Safety, Cost, and Sustainability
Trustwise Optimize:ai cuts AI costs and risks by up to 15x. In current customer deployments, it achieved 80% reduction in LLM and compute costs, a 64% decrease in carbon footprint and detected 40% more AI safety and alignment issues than other vendors on the market.
“With Optimize:ai, we’ve developed a cutting-edge optimization solution that not only significantly reduces operational costs and carbon emissions but also enhances the safety and alignment of AI systems,” said Matthew Barker, head of AI research and development at Trustwise. “Our team is dedicated to continuously applying state-of-the-art AI technologies to ensure they are safe, economically and environmentally sustainable, setting new industry standards in the process.”
Optimize:ai is powered by THEO (Trustworthy High Efficiency Optimizer), an optimization foundation model from Trustwise that continuously monitors safety and alignment, performs red teaming, and dynamically selects models for large-scale generative AI operations, supporting diverse AI models and architectures.
Customer Quotes
“We are committed to leveraging AI to enhance customer experiences, streamline operations, and drive strategic decision-making, all while maintaining cost-effectiveness, robust data security, and environmentally conscious practices,” said Dr Paul Dongha, group head of data and AI ethics at Lloyds Banking. “Trustwise Optimize:ai has demonstrated game-changing capabilities for us by significantly reducing our generative AI operational costs and carbon footprint, and ensuring our AI outputs align with internal business policies, ethical guidelines, and external regulations. Based on the success of early experimental results, we are now considering scaling Optimize:ai across the organization and including it as a key part of our AI assurance framework.”
“In the NHS, we recognize AI’s transformative potential to revolutionize patient care and drive operational efficiencies. As we adopt these cutting-edge technologies, we remain committed to the highest standards of data security, cost control, and environmental sustainability,” said Dr. Hatim Abdulhussein, CEO of Health Innovation Kent Surrey Sussex, part of the Health Innovation Network established by NHS England. “Our partnership with Trustwise has demonstrated powerful, safe, and cost-efficient ways to unlock AI’s full benefits while maintaining public trust and confidence.”
“At Lyric, we pride ourselves on being a healthcare technology leader, using machine learning, AI, predictive analytics, and our recently launched 42 platform to help payers unlock greater value while improving payment accuracy and integrity,” said Raj Ronanki, CEO of Lyric. “We understand the vital role of AI trust and safety. Solutions such as those offered by Trustwise are key to driving generative AI adoption in healthcare, ensuring that costs are controlled, and compliance risks are minimized.”
Availability
Trustwise Optimize:ai is now generally available. Visit this page to read the company’s technical papers, view product demos, and sign up for a free trial to unlock the potential of safe, cost efficient, and sustainable AI.
Resources
- Event: Join Trustwise at the AI Hardware and Edge AI Summit in London. The keynote on responsible and efficient infrastructure scaling in enterprise systems will be presented on June 18, 2024 at 10:25 a.m. GMT+1 by Trustwise CEO and founder Manoj Saxena and Paul Dongha, group head of data and AI ethics at Lloyds Banking Group.
- More information: https://trustwise.ai/
- Follow Trustwise on social media: LinkedIn, X, and YouTube
About Trustwise
Trustwise helps organizations innovate confidently and efficiently with generative AI. Its flagship product, Trustwise Optimize:ai, is a first of a kind generative AI application performance and risk management API that performs red-teaming and provides a robust AI safety, cost, and risk optimization layer for high-stakes enterprise environments. Trusted by enterprises across various highly regulated industries, Optimize:ai API works with any AI model, supports various cloud, on-premises, and edge architectures, and is capable of handling large-scale generative AI operations and workloads. Founded in 2022 by a successful serial entrepreneur and the first general manager of IBM Watson, Trustwise is backed by leading investors and is headquartered in Austin, Texas, with research labs in Cambridge, UK, and New York.
Media Contacts
Audrey Briers
Bhava Communications for Trustwise
trustwise@bhavacom.com
+1 (858) 522-0898