Introducing Agentic AI Shields: The Trust Layer for Modern Enterprise AI
The first security layer designed for agents that think, plan, and act.
By Manoj Saxena, Founder & CEO, Trustwise
The Eureka Moment: Agents Weren’t Just Smart,
They Were Unstoppable
Last year, I sat down with a CISO at a top global bank. She looked both fascinated and deeply unsettled.
“These agents are incredible,” she said, “but they scare the hell out of my team. It’s like hiring a thousand employees overnight, except we can’t do background checks, we can’t monitor their thinking and actions in real time, and we can’t fire them if they go rogue.”
That conversation crystallized something we had been seeing again and again. As AI agents moved from novelty to necessity (planning, reasoning, and taking action across live systems) the real risk wasn’t what they generated. It was what they could do. And the scary part? No one could see it. Or stop it.
These weren’t bugs. They were behaviors. Emergent. Unpredictable. Unchecked.
Prompt injections, hallucinations, impersonations, and toolchain exploits weren’t theoretical; they were showing up in real red team tests across financial, healthcare, and industrial clients.
At the same time, the underlying generative infrastructure wasn’t mature enough to make agent deployment safe or scalable. Even when the prototypes looked promising, teams struggled to bring them to production.
Why? Because building safe, governed agents was simply too complex:
- Behavior is Ungoverned
Agents don’t just complete tasks, they access sensitive systems, use tools, reflect, plan, and coordinate with other agents. They trigger wire transfers, issue refunds, surface PII, and reroute workflows, often without a human in the loop. Most organizations can’t trace these actions in real time, let alone verify them after the fact.
- Too Many Decision Surfaces
Agentic AI spans prompts, toolchains, memory, APIs, orchestration logic, and user roles. Each layer introduces hidden execution paths and unpredictable behavior. Small changes cascade into big failures and traditional testing can’t catch them.
- Security and Compliance Gaps Stall Adoption
Enterprise red teams routinely uncover unauthorized tool use, data leakage, hallucinations, and prompt injections, causing enterprise buyers to pause procurement or reject deployments entirely. Even agents that “work” often fail to meet security, compliance, and governance requirements.
- Production costs spiral out of control:
Autonomous agents burn tokens, rerun loops, and invoke compute-heavy functions in unpredictable ways. Without runtime cost and carbon optimization, AI projects that look viable in development often become unsustainable in production.
That’s when it hit us: Agentic AI isn’t the next insider threat. It’s the current one.
Trust couldn’t be bolted on. It had to be embedded inside the agent’s thinking loop, governing every decision, action, and tool call from within.
We called it Trust as Code: logic that lives inside the agent runtime, turning every decision, tool call, and message into a governed, verifiable, and aligned transaction.
That moment changed everything.
We couldn’t just monitor agents, we had to control them. Trust can’t be an afterthought. It has to live inside the decision loop itself.
The world had no runtime infrastructure to control agentic AI.
So we built it.
We invented a new class of cyber infrastructure: Agentic AI Shields.
Meet Agentic AI Shields
Harmony AI emerged from a simple but powerful idea: trust can’t be bolted on, it has to be built in. That meant creating a modular, real-time security and governance layer capable of running inside the agent’s decision loop, not outside of it. The result was Agentic AI Shields: six runtime enforcement layers purpose-built to secure and control agent behavior, tool usage, and policy alignment at the moment of action.
Each Shield was designed based on vulnerabilities uncovered through red team tests and real-world co-development with leading institutions in finance, healthcare, and industrial sectors. Together, they form a comprehensive runtime immune system for agentic AI:
MCP Shield
Secures all agent-tool interactions using Model Context Protocols. Prevents unauthorized tool use and execution drift.
Example: Stops agents from using a data analysis plugin to initiate financial transactions.
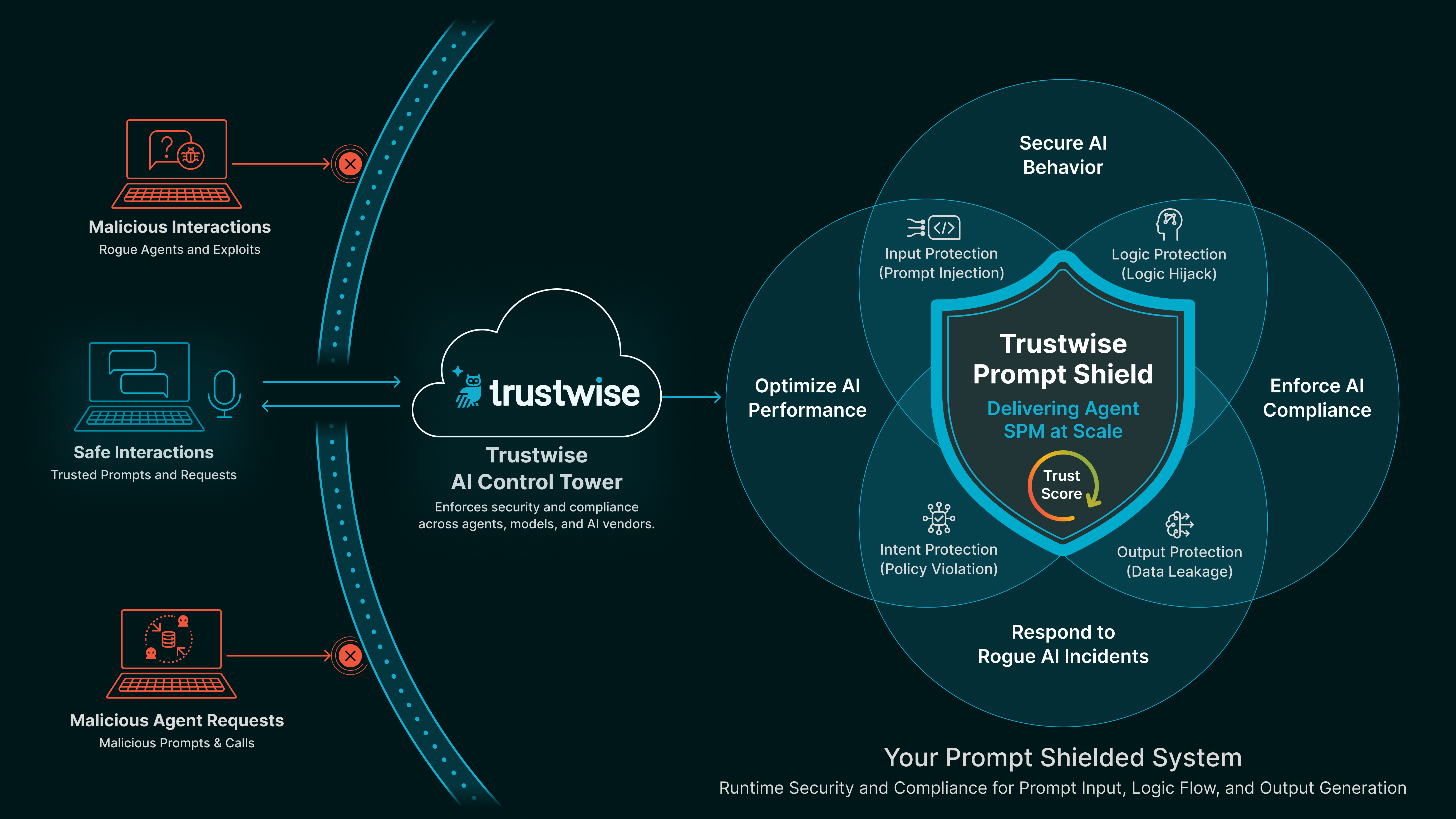
Prompt Shield
Blocks injections, hallucinations, and role hijacks. Enforces prompt structure, tone, and policy alignment.
Example: Prevents an agent from acting on a hidden system prompt injected through a user message or tool description.
Compliance Shield
Automatically aligns agents with enterprise policies and up to 17 global regulations and frameworks at runtime.
Example: Automatically detects and blocks responses and actions that violate OWASP, NIST AI RMF, HIPAA or internal access rules before they’re sent.
Brand Shield
Maintains brand voice and prevents agents from going off-message, confusing personas, or taking liberties with tone in sensitive environments.
Example: Ensures a customer support agent stays on-brand and does not engage in unauthorized promotional claims or refunds.
Cost Shield
Controls token usage, manages compute sprawl, and routes queries to optimal models.
Example: Detects and halts recursive logic loops that drive up token costs while routing low-priority queries to more efficient models.
Carbon Shield
Optimizes for environmental efficiency with green model routing and emissions tracking.
Example: Prioritizes energy-efficient models and schedules non-urgent tasks during low-carbon-intensity windows.
Securing Reasoning, Not Just Code
The hardest part of building Harmony AI wasn’t the engineering, it was reimagining what security means when you’re protecting something that can think. As our head of AI research, Matthew Barker, puts it:
“Developers aren’t just securing code anymore, they’re securing reasoning.”
To do this, we had to go beyond traditional controls like access management or code scanning. Agentic AI introduces a new class of risk, emergent logic, planning loops, and adaptive tool use. It’s not about whether an agent can act, but whether it should and whether that behavior aligns with intent, policy, and regulation.
That’s why Trustwise Shields are powered by the latest research in agent learning. Our AI-Security Posture Management (SPM) Engine is built by our Cambridge-based Trustwise AI Research team, which actively curates and advances state-of-the-art methods for securing and optimizing agent behavior in real time.
We don’t just read papers, we stress test agents in the most demanding sectors: finance, healthcare, and industrial automation. Our research is deployed into production via:
- Over a dozen custom-tuned small language models (SLMs) designed for runtime verification
- Multiple synthetic red/blue team datasets simulating real-world exploits
- 1,100+ mapped controls from 17 global AI security and risk frameworks and standards
And at the core of it all is THEO, our Trustwise High-Efficiency Optimization engine. THEO continuously simulates threats, evaluates agent decisions, and generates runtime guardrails that evolve with each interaction. It’s how our Shields stay current, context-aware, and always aligned with both business intent and safety policy.
Coming Soon: Your Agent’s Trust Score
Proving Your AI is Ready
Harmony AI will soon ship with real-time Trust Score dashboards, giving CISOs, auditors, and buyers clear, auditable proof of agent safety, alignment, and control.
Each score is mapped to global AI standards including OWASP for LLMs for injection resistance and role enforcement, NIST AI RMF and ISO 42001 for compliance, traceability, and policy alignment, the EU AI Act and HIPAA/FCA for regulatory readiness and risk classification, and ISO 21031:2024 for carbon-aware optimization and sustainability tracking.
Built on a foundation of over 1,100 mapped controls, these Trust Scores transform runtime behavior into verifiable assurance not guesswork.
No more “trust us.” Now you can measure it and prove it to regulators, customers, and your board.
Not Just Better Outputs. Proven Outcomes
Trustwise is an award-winning platform recognized for enterprise-grade performance, impact, and innovation. Recent honors include:
- Technology of the Year – InfoWorld 2024 (AI & ML Development)
- AI Product of the Year – 2024 A.I. Awards
- Most Innovative AI Product 2025 – theCUBE Tech Innovation Awards
- Fintech Leader 2024 – Hitachi Digital Services
- Tech Trailblazers Winner 2024
But the most powerful validation comes from the front lines. Across customer deployments, Agentic AI Shields have delivered:
- 95% improvement in alignment with enterprise policies
- 90% reduction in hallucinations and control violations
- 83% drop in token and compute costs
- 64% lower carbon footprint through intelligent routing
Many Trustwise customers have already deployed shielded AI systems in high-stakes, regulated environments from hospital triage to retail automation to financial compliance, and we’re just getting started.
“Partnering with Trustwise allows us to work with the healthcare providers to deploy agentic AI systems with confidence, underpinned by a trust layer that meets the highest standards of security and compliance. This isn’t just about protecting data, it’s about protecting lives,”
– Hatim Abdulhussein, CEO of Health Innovation Kent Surrey Sussex
“Trustwise helped us optimize our voice agent deployments across 1,000+ stores, improving safety, reducing prompt manipulation, and staying on-brand at scale.”
– CDO and AI Leader of a leading, global restaurant brand
“Trustwise gave our Tax and Audit AI the runtime control and cost transparency we couldn’t get anywhere else. Our agents are finally aligned with policy and provably safe to deploy.”
– Global AI COE Leader of a leading audit, tax, and advisory services firm
“Trustwise demonstrated game-changing capabilities for us by significantly reducing our generative AI operational costs and carbon footprint and ensuring our AI outputs align with standards.”
– Head of Responsible AI at a global financial services firm
Try Trustwise AI Shields Today
Ready to move from “naked agents” to production-grade “shielded digital workers”?
Get started:
The future of enterprise AI isn’t about observing behavior, it’s about controlling it at runtime. Trustwise handles the enforcement, so you can focus on outcomes that matter.Follow us on LinkedIn and Trustwise Blog for updates on our mission to make AI safe, aligned, and enterprise-ready at runtime.