Trustwise Reports Strong Enterprise Momentum as Trust Posture Management Becomes Critical for Agentic AI.
READ MORE
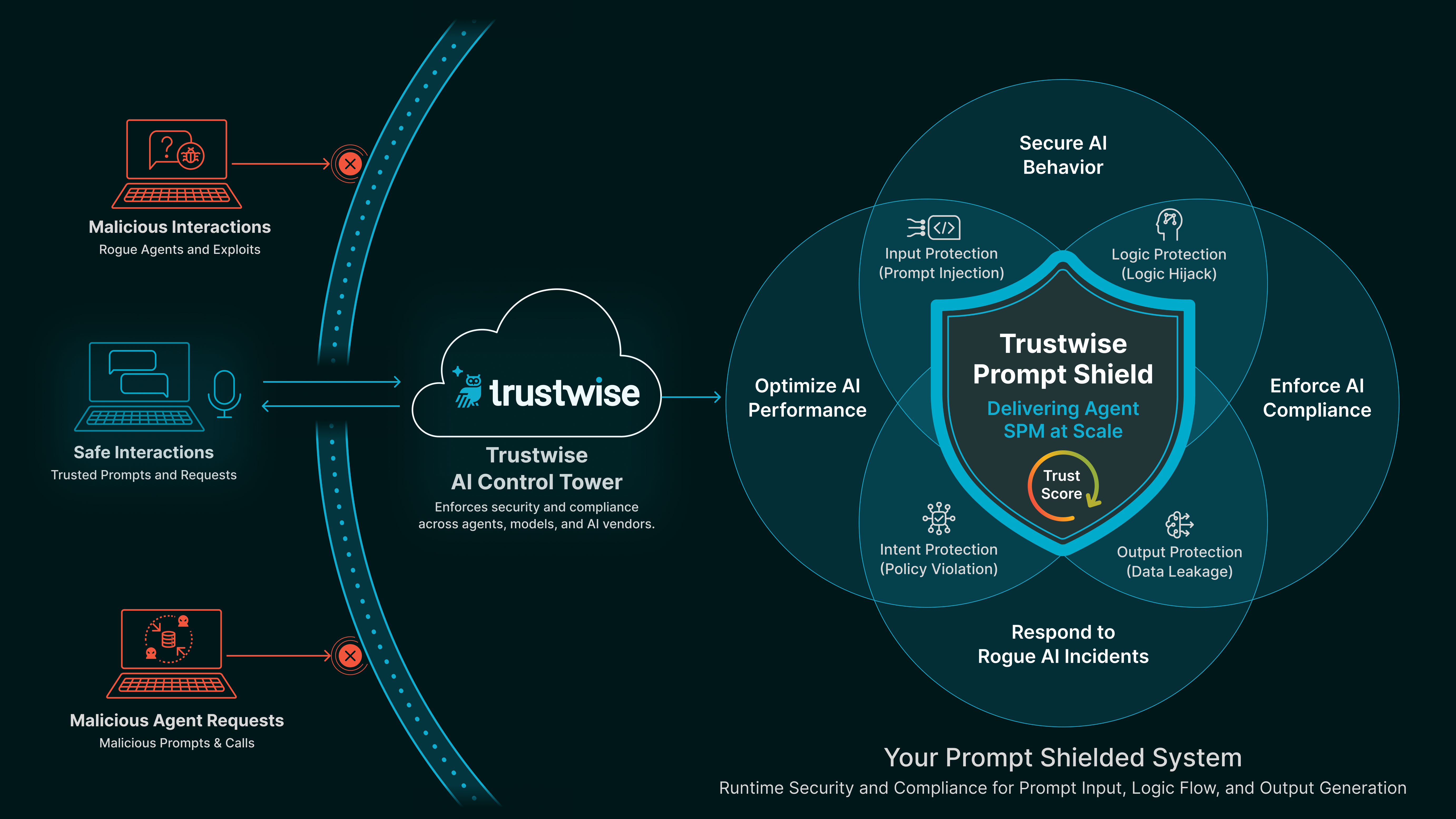
Your firewall doesn’t speak Prompt. Trustwise does.
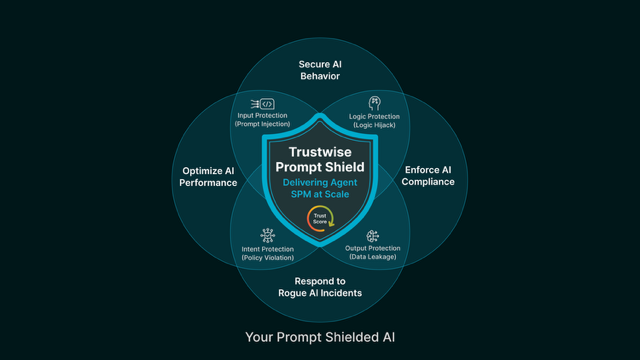
Prompt Shield enforces secure and compliant AI behavior by protecting prompt input, logic flow, and output generation in GenAI and Agentic systems.
Prompt Injection Is the Fastest-Growing Threat in AI Security
LLMs are programmable with natural language and so are the attacks. Without protection, adversarial prompts can hijack your AI system, leak sensitive data, and bypass your guardrails in seconds.
Trustwise Prompt Shield Stops the Attacks Others Miss:
- Jailbreaks and system override attempts
- Prompt injection into memory and multi-turn logic
- Exposure of prior prompts or sensitive data
- Abuse of tools, plugins, APIs, or autonomous actions
- Malicious tool chaining and lateral prompt escalation
“Prompt Shield gave us confidence to roll out agents without worrying about jailbreaks or data exposure.”
— Head of Platform Security, Fortune 100 Financial Services
What Makes Prompt Shield Different
Automated Red & Blue Teaming
Simulate real-world prompt attacks and defenses with built-in red teaming and defense benchmarking.
Complete Input/Output Defense
Every prompt is shielded in real time covering prompt injection, policy violations, and regulatory compliance.
Built-in Benchmarking
Prompt Shield delivers automated benchmark generation and real-time defense for complete coverage from day one.
Automated Red & Blue Teaming
Generate comprehensive prompt security and output compliance benchmarks automatically. Red team attack scenarios, blue team defenses all built-in for instant prompt protection.
Cover Every Prompt Surface
Input, Logic, Output
Deliver real-time protection and compliance across all prompt-driven behaviors, from initial instruction to final response.
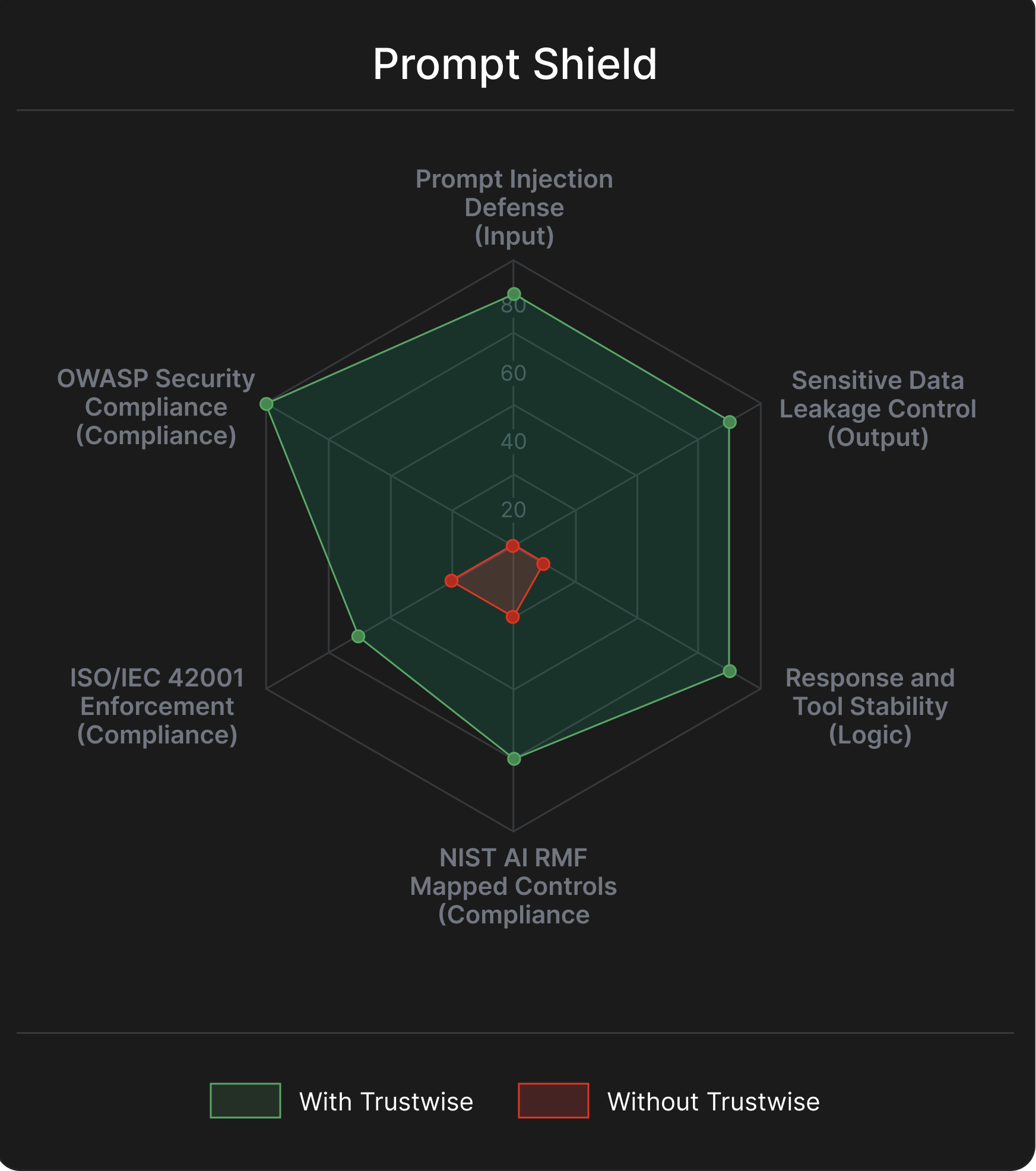
Built-in AI Trust Benchmarking
No manual testing required. Prompt Shield delivers automated benchmark generation and real-time defense complete coverage from day one.
How our Harmony AI Shield Works
Install and get started in seconds
Easy Python installation with pip, REST APIs available for other languages. Test it out with our examples or your agents…
Sign up today and get your free API key from the Trustwise team
*Trustwise is committed to protecting and respecting your privacy, and we’ll only use your personal information to administer your account and to provide the products and services you requested from us. By clicking submit below, you consent to allow Trustwise to store and process the personal information submitted above to provide you with the content requested.